Reinforcement learning has achieved striking results in classic games like Go and Chess, but multi-player board games with rich player interaction remain challenging. In this project we study RL agents for Catan, a four-player, turn-based strategy game where players build roads, settlements, and cities to reach a target victory-point score.
Our original goal was to train multi-agent policies using algorithms from MARLlib in a custom PettingZoo environment. In practice, library assumptions about parallel agents and synchronous play conflicted with Catan’s sequential, turn-based structure. Even after extensive engineering and masking, MARL methods failed to converge.
To still obtain quantitative results, we pivoted to a single-agent PPO baseline in a simplified Catan setting: no trading, adjustable victory conditions, and dense reward shaping. The resulting agents learn to shorten games and accumulate more victory points than random baselines, but still struggle to consistently win against evolving opponents. The gap between these results and our original MARL goals highlights both the promise and the difficulty of learning in non-stationary multi-player environments.
We started from the open-source Settlers-RL implementation and refactored it into a cleaner, modular codebase suitable for both single-agent and multi-agent RL experiments. The project has three main pieces:
Catan is modeled as a turn-based multi-agent environment using the Agent Environment Cycle (AEC) API from PettingZoo. Each agent can take multiple actions in sequence on a turn (roll dice, move the robber, build, buy cards, end turn, etc.), which we expose through a structured observation and action design.
Each agent observes a single flat vector with three components:
This encoding stays compact but still lets the policy reason about long-term plans such as expanding toward high-yield tiles or blocking key intersections.
We parameterize the action space with seven separate action heads, so the agent can compose complex moves while still sharing context across related decisions:
These heads are concatenated into a 172-dimensional action vector, mirroring the observation representation and letting the network learn coordinated strategies across heads.
Sparse “win or lose at the end” rewards make long Catan games difficult to learn from. We instead use a dense reward signal that gives feedback at each step:
In practice, these shaped rewards help the agent discover the game structure faster, while still aligning long-term behavior with the goal of winning.
We first evaluated MAPPO and other MARL algorithms from MARLlib on simpler tasks (e.g., a multi-particle “simple-spread” environment) and observed stable convergence. But when plugged into Catan, MARLlib’s assumption of parallel, synchronous agents conflicted with our sequential AEC environment. Observations would become stale between turns, leading to illegal actions and non-convergent training even with aggressive masking and hyperparameter tuning.
To still measure learning progress, we implemented PPO directly in PyTorch and trained a single agent in two settings: standard 10-point Catan and a faster 4-point version for quicker curriculum-like experiments. Aggregated metrics across training show:
The plots below mirror Figures 4–6 in the report and summarize how our PPO agent behaves in both 10-point and 4-point Catan.
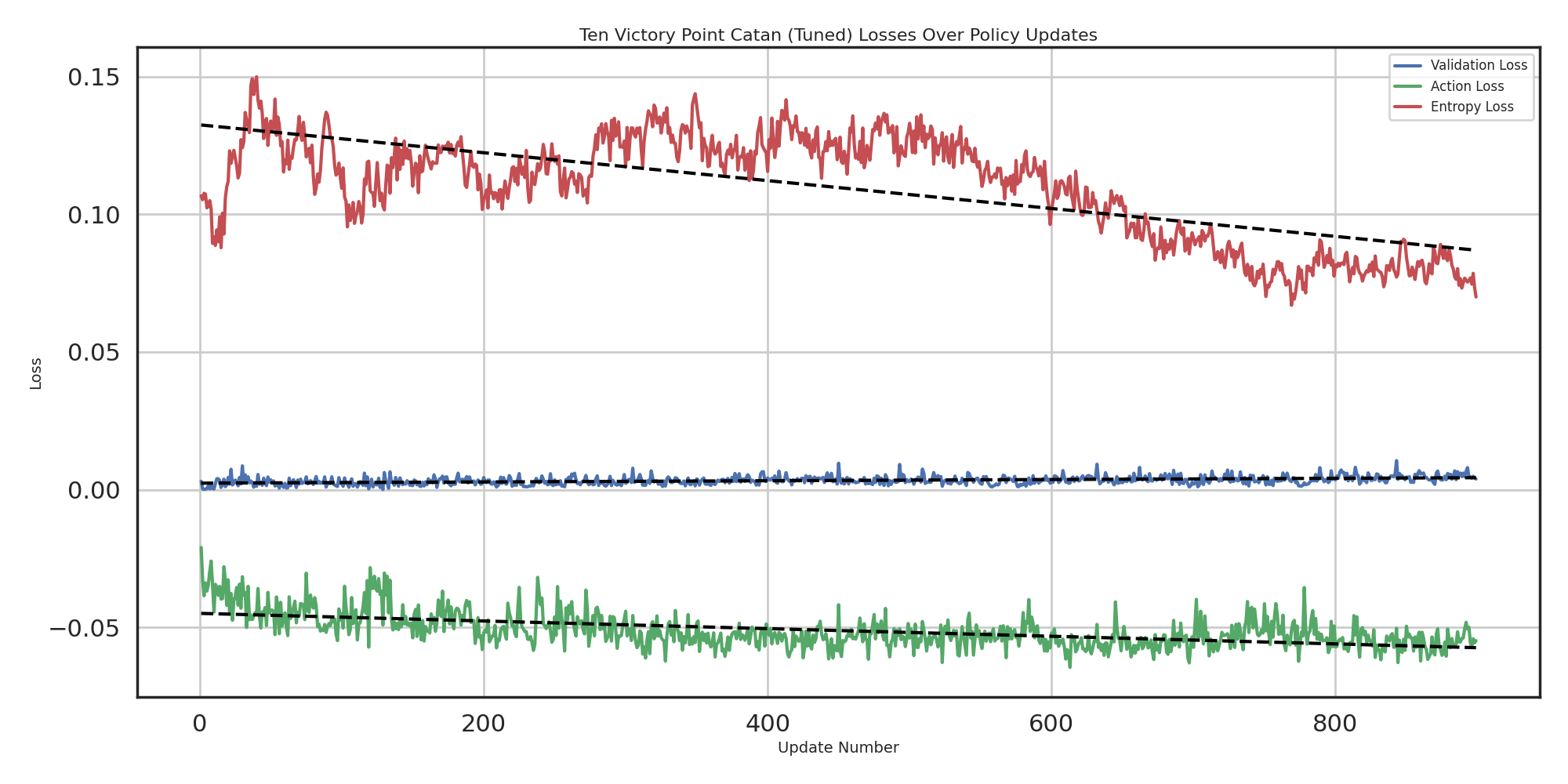
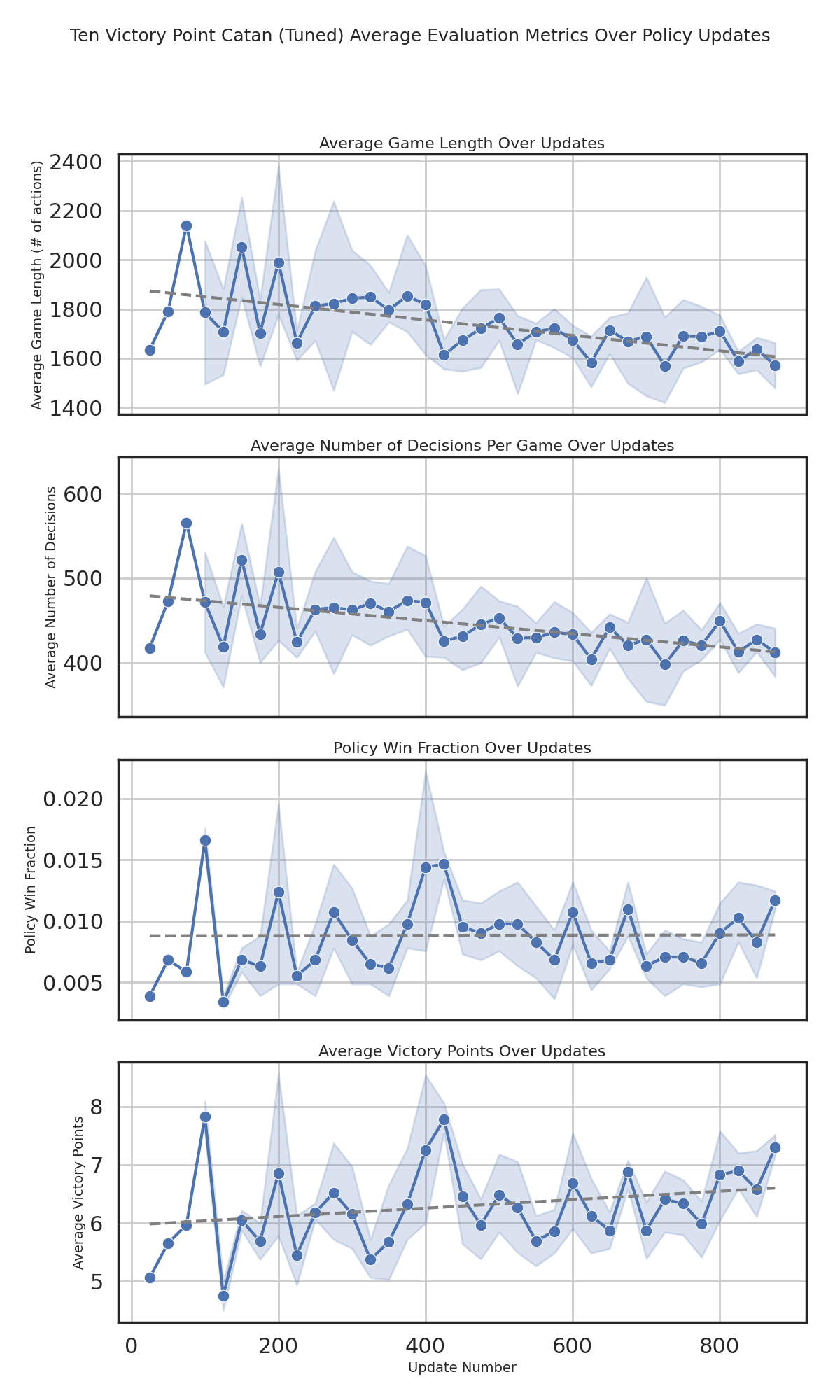
Games get shorter and require fewer decisions, and average victory points rise, but the win rate against baselines only improves slightly. This suggests the agent learns more efficient play without reliably converting that into consistent wins against strong opponents.
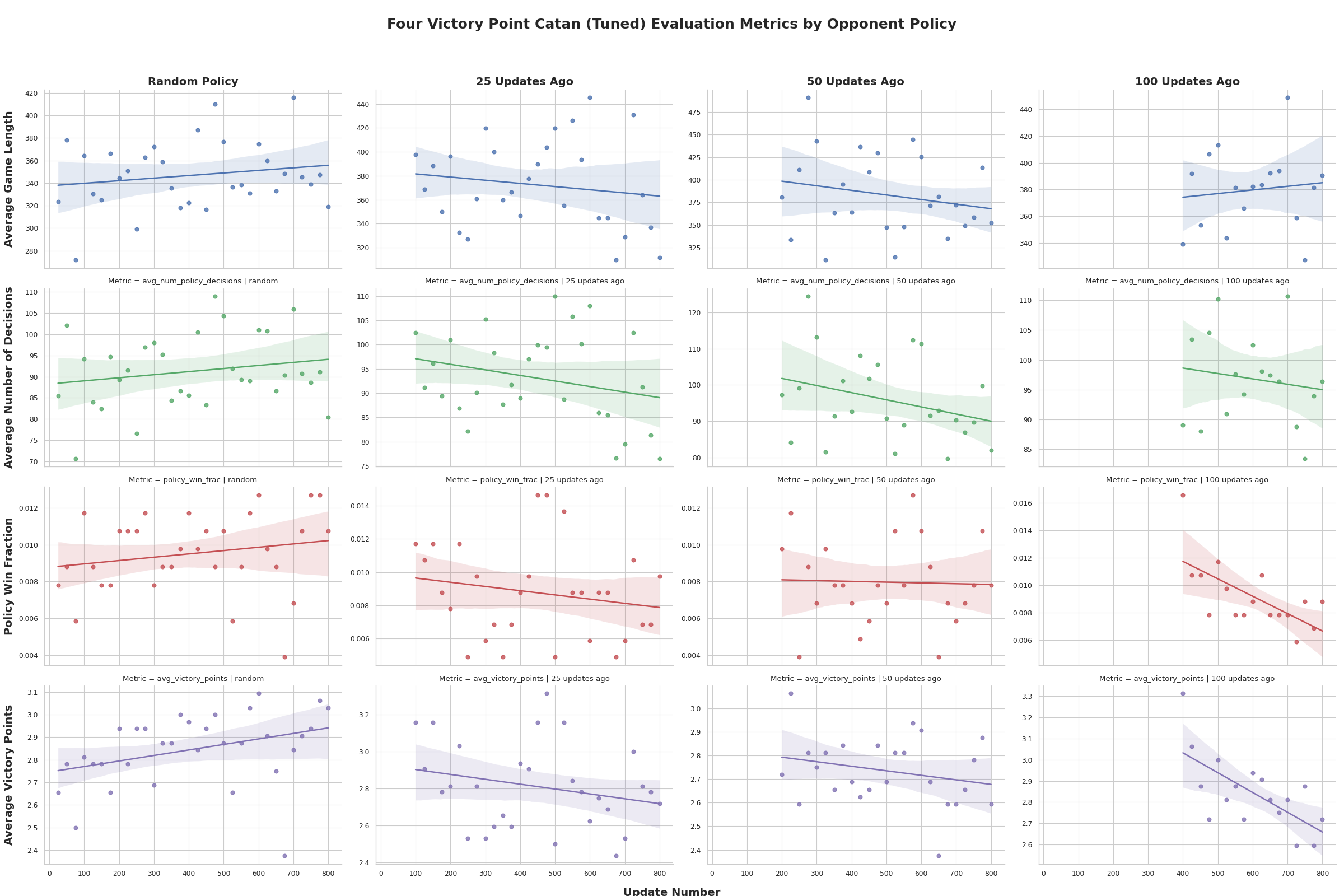
The single-agent PPO results suggest that optimizing against a mostly static environment is not enough: Catan’s difficulty lies in evolving opponent strategies and the resulting non-stationary dynamics. Our experiments reinforce that truly strong Catan agents will likely need full multi-agent methods or explicit modeling of other players, not just a stronger single-agent baseline.
The clip below shows an RL agent playing through a full game of Catan in our environment. The board, dice rolls, robber moves, and building decisions are all driven by the learned policy.
A higher-resolution version is also available in the repository as
gameplay-rl-agents.mp4.
If you use this environment or codebase in your own work, please consider citing our webpage.